Importance sampling placement in TDRC
Temporal-Difference Learning with Regularized Corrections (TDRC) is one of the few stable algorithms for learning a value function off-policy with function approximation (e.g., neural networks, tile coding, radial basis functions, etc.). “Stable” in this case means the expected update over the state distribution is a contraction, and applying the update will decrease error in expectation. Some of the most popular value function learning algorithms like Retrace/V-trace are not stable and are not guaranteed to reduce error or converge when used with function approximation. This is an absolutely crucial property for a learning algorithm to have, especially if it’s going to be used in real-world applications.
TDRC and its predecessor TDC achieve stability and avoid the Deadly Triad by retreating from TD-style semi-gradient updates and instead performing approximate gradient updates. The updates are only approximate because it turns out to be extremely difficult (impossible?) to get an unbiased estimate of the gradient in any realistic setting due to the double sampling problem. Instead, TDC and TDRC use regression to learn a parametric estimate of the expected TD error for each state, and use this estimate in place of the missing sample.
TDC
The TDC update rules from Reinforcement Learning: An Introduction (Sutton and Barto, 2018) are:
\[\begin{align} \vw_{t+1} &= \vw_t + \alpha_\vw \rho_t \delta_t \vx_t - \alpha_\vw \rho_t \gamma_{t+1} \left(\vh_t^\T \vx_t\right) \vx_{t+1} \\ \vh_{t+1} &= \vh_t + \alpha_\vh \rho_t \left(\delta_t - \vh_t^\T \vx_t\right) \vx_t \end{align}\]where $\vw$ is the vector of parameters for learning the value function, $\vh$ is the vector of parameters for learning the expected TD error, $\vx$ is the vector of features representing the (unobservable) state, $\delta$ is the TD error, $\rho$ is the importance sampling ratio that corrects for actions being sampled from the behaviour policy $\mu$ instead of the target policy $\pi$, $\alpha_\vw$ and $\alpha_\vh$ are free step size parameters, and $\gamma$ is the discount parameter. Then $\vh^\T \vx$ is an estimate of the expected TD error.
The first update rule $(1)$ has a couple things going on. Its second term $\left(\alpha_\vw \rho_t \delta_t \vx_t \right)$ is the off-policy TD update, which itself is the on-policy semi-gradient TD update scaled by the importance sampling ratio $\rho_t = \frac{\mu(A_t \vert S_t)}{\pi(A_t \vert S_t)}$ to correct for the fact that the behaviour policy is choosing actions with a different probability than the target policy would. This off-policy TD update alone is not stable when used with function approximation and may cause the value function weights $\vw$ to grow to infinity. To overcome this issue, TDC and TDRC attempt to correct the semi-gradient update by subtracting an estimate $\left(\alpha_\vw \rho_t \gamma_{t+1} (\vh_t^\top \vx_t) \vx_{t+1}\right)$ of the missing term that would make the update rule a stochastic gradient update.1 The second update rule $(2)$ operates on the second set of weights $\vh$, which tries to learn the required estimate of the missing term using stochastic gradient descent.
TDRC
TDRC goes a step beyond TDC, recognizing that for the true value function there is zero expected TD error and therefore the second weight vector $\vh$ should eventually go to $\v{0}$—assuming the function approximator can represent the true value function. Therefore, performance can potentially be improved using L2 regularization to encourage $\vh$ to be closer to $\v{0}$. The TDRC update rules from the paper are:
\[\begin{align} \vw_{t+1} &\gets \vw_t + \alpha \rho_t \delta_t \vx_t - \alpha \rho_t \gamma_{t+1} \left( \vh_t^\top \vx_t \right) \vx_{t+1} \\ \vh_{t+1} &\gets \vh_t + \alpha \left[ \rho_t \delta_t - (\vh_t^\top \vx_t) \right] \vx_t - \alpha \beta \vh_t \end{align}\]where $\alpha$ is the lone free step size parameter and $\beta$ is a regularization parameter controlling the tradeoff between minimizing error and keeping the weight vector $\vh$ close to $\v{0}$.
Comparing the two sets of update rules, there are several things to notice. First, the TDRC update rule for $\vw$ is exactly the same as that of TDC. Second, the update rule for $\vh$ is quite a bit different from that of TDC. There’s an additional regularization term $\left(\alpha\beta\vh_t\right)$ being subtracted from the regression loss to encourage $\vh$ to remain close to $\v{0}$. In addition, the regression loss term itself is slightly different in each of the update rules for $\vh$. Specifically, the importance sampling ratio $\rho$ is scaling the TD error $\delta$ in the TDRC update rule $(4)$, whereas it scales the entire loss term (including the estimated TD error) in the TDC update rule from the textbook $(2)$.
Because $\E{\mu}{\rho_t} = \E{\mu}{\frac{\pi(A_t,S_t)}{\mu(A_t,S_t)}} = \sum_a \mu(a \vert S_t) \frac{\pi(a \vert S_t)}{\mu(a \vert S_t)} = \sum_a \pi(a \vert S_t) = 1$, both updates are the same in expectation. However, their variances may be different, which leads us to the first question investigated in this blog post.
Which update rule should be preferred?
On one hand, the book’s version could perform better because the estimated TD error is now the same scale as the observed TD error, meaning the difference between them is likely smaller, yielding smaller changes to the weights. On the other hand, intuition is often wrong. To get some insight, I empirically compared the version of TDRC in Equations $3$ and $4$ (denoted TDRC in the plot below) with a version of TDRC using the update rule from Equation 2 (denoted TDRC2 in the plot below), but with the regularization term $(\alpha\beta\vh_t)$ introduced.
I compared the two variants of TDRC on the version of Baird’s counterexample detailed in Figure 11.1 of the RL:AI textbook.
I ran each algorithm 50 times with the following constant step sizes: 1.0, 0.5, 0.25, 0.125, 0.0625, 0.03125, 0.015625, 0.0078125, 0.00390625, 0.001953125, 0.0009765625, 0.00048828125, 0.000244140625, 0.0001220703125, and plotted the learning curve for the best-performing step size in the graph below (shaded regions are 95% confidence intervals).
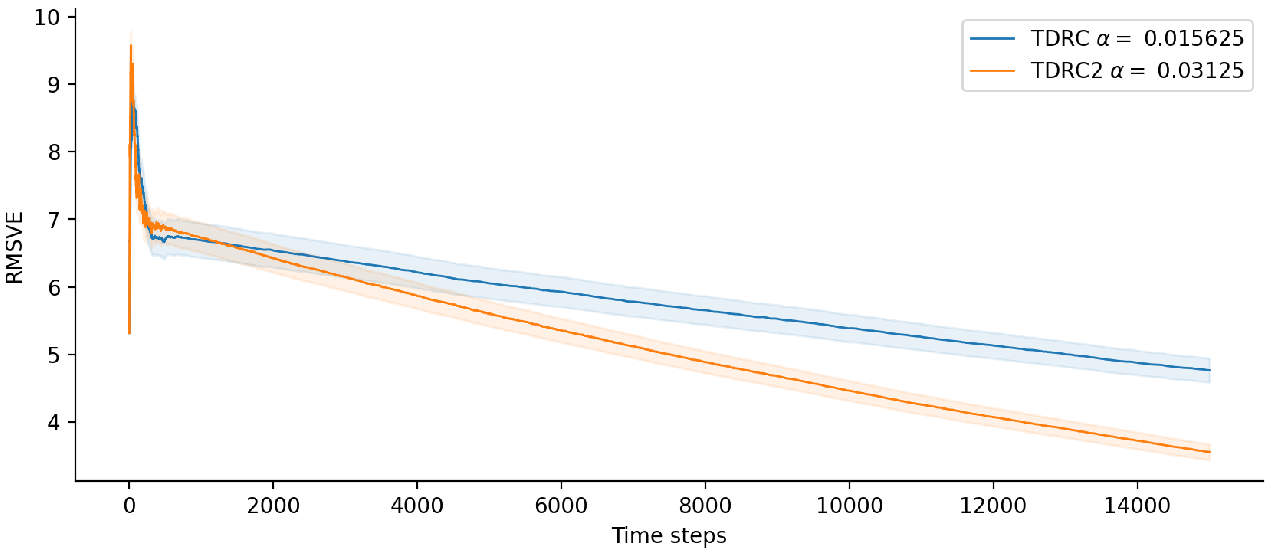
On Baird’s counterexample, the version of TDRC using the textbook’s importance sampling ratio placement appears to outperform the original version in the long run. However, early in learning it’s not clear which variant is better.
If the version of TDRC that scales the whole error term by $\rho$ indeed performs better than the original version, shouldn’t the regularization term also be scaled by $\rho$? If the regularization term is not scaled by $\rho$ and $\rho$ is small, then the update would mostly try to shrink the weights. Conversely, if $\rho$ is large, then the update would mostly try to reduce the estimation error. However, if the regularization term IS scaled by $\rho$, then the relative contribution of the regularization to the update would be consistent regardless of whether $\rho$ is large or small. On the other hand, this inconsistency might only have a small effect or might not end up mattering at all.
Should the regularization term also be scaled by $\rho_t$?
So I ran both variants on Baird’s counterexample, using the book’s update rule for $\vh$. TDRC (blue) in the plot below does not scale the regularization term by $\rho_t$, while TDRC2 (orange) does.
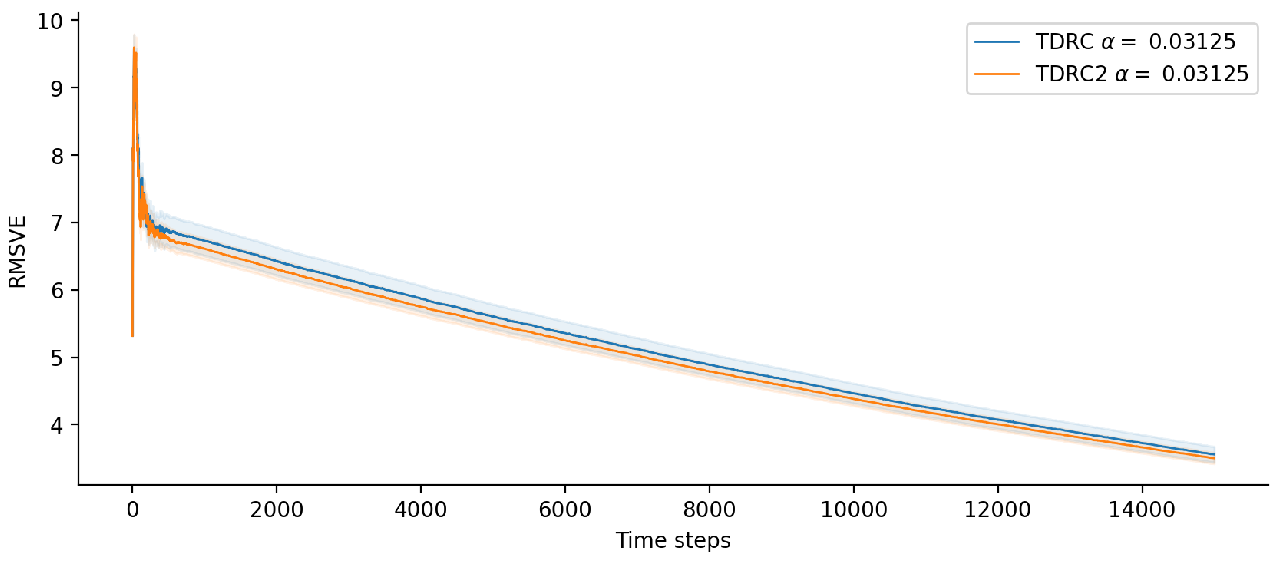
Over the course of the experiment, the variant of TDRC that scaled the regularization term seemed to perform very slightly better than the version that didn’t, with slightly lower error and variance. However, the difference wasn’t large enough to be statistically significant.
Next steps
The most important next step is to re-run these tests on another environment, as Baird’s counterexample is pretty contrived and algorithms that perform well on it tend to perform poorly on real environments, and vice versa.
Footnotes
-
I’m curious whether the bias introduced by re-using a single sample of the TD error is lesser or greater than the bias introduced by using a learned parametric model of the expected TD error. On one hand, the re-use bias never goes away, while the parametric model’s bias may diminish over time (assuming the function approximator is powerful enough). On the other hand, in real world applications the function approximator is typically not powerful enough to achieve 0 error. ↩